 ���ں�
���ں�������ʱ���µ��û���˽���� �����˽�ܳ�Ϊ"��������"��?
2018-01-24 14:36:33
- +1 ������
���켫������Ƶ�������죬���ݳ�Ϊһ�ֱ����ʲ���������ҵ�������ȿֺ���ռ��û���Ϣ��һ���棬�û���Ϣ�ܹ�Ϊ��ҵ������ֵ������ҵ�ɽ�����ҵ�������Ľ���Ʒ��ҵ������һ���棬��ҵҲ������û���Ϣ��й¶��Σ���û�������˽��
����ȿ�������ҵ�����ʶȵ��ռ��û���Ϣ���ֲ�����й¶������˽��������Ϊ����������ҵ���ٵ����⣬ҲӰ���Ŵ�������ҵ�ķ�չ��

2016��6�£�ƻ����˾��ȫ���ߴ�����״�����˲����˽����(Differential Privacy)���������ܹ�ͨ������ѧ�㷨���û������ݽ��С����ܡ��ϴ���ƻ����������ƻ������ͨ����Щ�����ܡ��������ݼ�����û�Ⱥ�����Ϊģʽ�����Ƕ�ÿ���û������������������
���ݵ�ʱƻ������ý����ʼ����������ͣ�
��iOS 10��ʼ��ƻ����ʹ�ò����˽�����ڲ�Ӱ�������˽��ǰ���°������ִ������û���ʹ��ģʽ��Ϊ���ڸǸ������ݣ������˽�������ʹ��ģʽ��С������ע����ѧ���������Ÿ�����û����ֳ���ͬ��ģʽ������ģʽ�ͻῪʼ���֣������������ǿ�û����顣��iOS 10���У�����������������QuickType�ͱ��齨�飬Spotlight������ӽ���ͱ���¼�е�Lookup Hints��
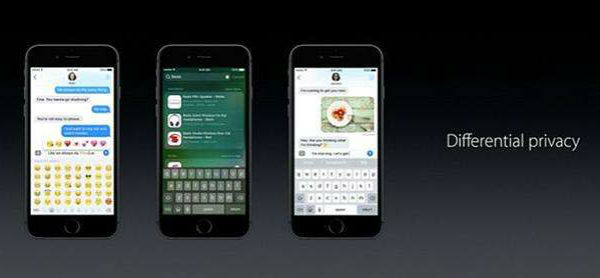
ʵ���ϣ�ƻ������ġ������˽�������õ�һЩ�˵���ͬ������ijЩ��������ɡ���ȹȸ��Facebook��ƻ������һ�ֺܲ��������������ǣ�����û�б���ȫչ�����û���ǰ��ƻ��һֱ�������������С���
���ȥ���⡰�ȿ��Է����������ݣ��ֲ������û��ĸ�����Ϣ����֪������ΪKyon�����ѽ��͵��������������빫��һ�����ݼ��������������ݷ������������뱣������ÿһ���������Ϣ��й¶����ôһ�ֿ��е��ֶξ��Ǹ�������ݼ�ע��һЩ��������˵�Ŷ�����Ȼ����Ŷ��������ӣ��������ݾ�ɥʧ�˿����ԡ�Ȼ���Ŷ�Ҳ����̫С���������������˽�������ˡ�
ͨ��������������Ʊ�֤��һ�����ݼ���ÿ�����嶼����й¶�������ݼ������ͳ��ѧ��Ϣ(�����ֵ������)ȴ���Ա�����˽⡣��ˣ�����һ��ҽ�ƻ���Ҫ�������ߵļ������ݸ�����Թ��о����Ϳ����ȶ�������ݼ���һ�����㡰�����˽�����Ŷ����ٹ�����ȥ��

����ΪNemo��֪��������ָ���������˽�������㣺���ڶ��ڱ���֪ʶ�ļ������ǿ����Ҫ�ڲ�ѯ����м����������������������ݵĿ����Լ����½����ر������Щ���ӵIJ�ѯ����ʱ���������������ڸ�����ʵ�������Ҳ�ǵ���ĿǰӦ�ò����һ��ԭ��
����֮����ijЩ��ҵ��˵�������˽��ʵ���Բ��ߣ�ԭ��������������ʹ���˲����˽�������л�ø����м�ֵ����Ϣ��
�ڱ��߿����������˽��ijЩ�����ܹ����Ӻܺõ����ã�����ȴ��������ҵ��ҵ��ֵ����ս����ˣ�������Σ��ⱳ������ҵ����ҵ��ֵ����ҵ���µĺ��������











����
������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼































